
GET IN TOUCH
We take pride in personally connecting with all interested partners, collaborators and potential clients. Please email us with a brief description of how you would like to be connected with Galois and we will do our best to respond within one business day.
Escaping Isla Nublar: Coming around to LLMs for Formal Methods
Until recently, I felt toward researchers using LLMs how Ian Malcolm felt toward scientists creating the dinosaurs of Jurassic Park: “Your scientists were so preoccupied with whether or not they could, they didn't stop to think if they should.” Like many formal methods people, I viewed LLM applications as more of a dull inevitability than an exciting prospect. Even modulo moral qualms surrounding plagiarism and environmental impact, I considered LLMs clumsy and inelegant, the modern equivalent of monkeys on typewriters.

Though life…uh…found a way to make me work with LLMs, my project found a way to foster a begrudging appreciation for the monkeys. During my summer internship at Galois, I built CNnotator, a tool that utilizes LLMs to generate memory safety annotations for C code. My tool worked a lot better than I was expecting it to, creating successful annotations despite its simple core structure and little work on prompting. I was also pleasantly surprised to see that even older LLMs worked shockingly well.
I have thus shifted from always protesting to occasionally, warily proselytizing the usage of LLMs for some formal methods research. If you’re a formal methods lover, I hope to convince you that accepting LLMs isn’t contradictory to that. LLMs can’t and shouldn’t try to solve every problem, but when combined with formal methods, they really can be useful.
Translation issues
Case in point–translating from memory-unsafe to memory-safe languages.
Some context: memory safety issues in older languages like C and C++ frequently make up the majority of security bugs in a system, as high as 70% of Chromium’s bugs. Modern languages, like Java and Rust, have built in mechanisms that prevent nearly all such bugs. Thus, all we need to do is translate legacy code into modern languages. There are several ways we might go about this, as listed in the table below:

We need to automate translation, because, well…

Symbolic methods of translation, like C2Rust, Corrode, and Citrus, translate C to Rust, but to unsafe, unidiomatic Rust with the idea that additional intervention would be required to create guaranteed-safe, idiomatic code. LLMs on their own translate C into idiomatic Rust code they claim to be valid and equivalent, but are less trustworthy than Dennis Nedry with $1.5 million on the line. If we could combine these approaches, however, we can counteract their failings: the LLMs will create idiomatic code, and the formal methods ensure that the code maintains functionality.
We already have early prototypes demonstrating that this idea yields results: C2SaferRust combines C2Rust, LLMs, and formal methods, and shows some impressive results. However, there’s still a lot of research to do before any fully automated tool can decisively tackle the steaming piles of C code in the wild.
CNnotator: Sees C and Notates CN for C
One of the biggest hurdles in translating C to Rust is figuring how a given C program is manipulating memory. C programs do a lot of weird things with memory, but LLMs are pretty good at understanding code. Could we get an LLM to determine exactly what those weird things are, and then use formal methods to check if it got the answer right?
This is the question I spent my summer internship at Galois researching. I built CNnotator, a command-line tool that automatically synthesizes annotations describing memory use for each function in a C project. Instead of trying to jump directly from C to Rust, CNnotator figures out the memory shape of the original C program. Our hope is once that’s done, translating to safe Rust should be much easier.
My tool generates annotations written in the C specification language CN. If we can synthesize a set of annotations that the CN tool approves, the code cannot raise C undefined behaviors or generate memory safety errors, like use-after-free bugs. That’s a very similar property to the one that safe Rust enforces by default–memory safety, with strict ownership requirements for pointers passed around, allocated, and freed.
CNnotator is structured as a simple loop:
- Pick a function dealing with memory ownership to focus on.
- Ask the LLM to generate a CN annotation for said function.
- Test the annotation against the CN tool.
- Iterate on the annotation or go back to 1.
LLMs don’t know CN by default, so we give it a tutorial to reference. This tutorial takes the form of a specification rules document that I created, the structure and much of the text of which is scraped directly from the CN tutorial.
In stage (3), we test the candidate annotation using CN’s property based testing capability. This means that CN builds a memory state that matches the precondition, then runs the function, checking at every stage that the memory is managed correctly. CN also offers a formal verification capability for annotations, but we didn’t use it for CNnotator because it would have required us to generate loop invariants and other annotations within the function body.
At the end of the loop, CNnotator provides the user with a fully annotated C project. Once we get this, we’re a lot of the way to creating safe, idiomatic Rust code–we hope to get to this in future work.
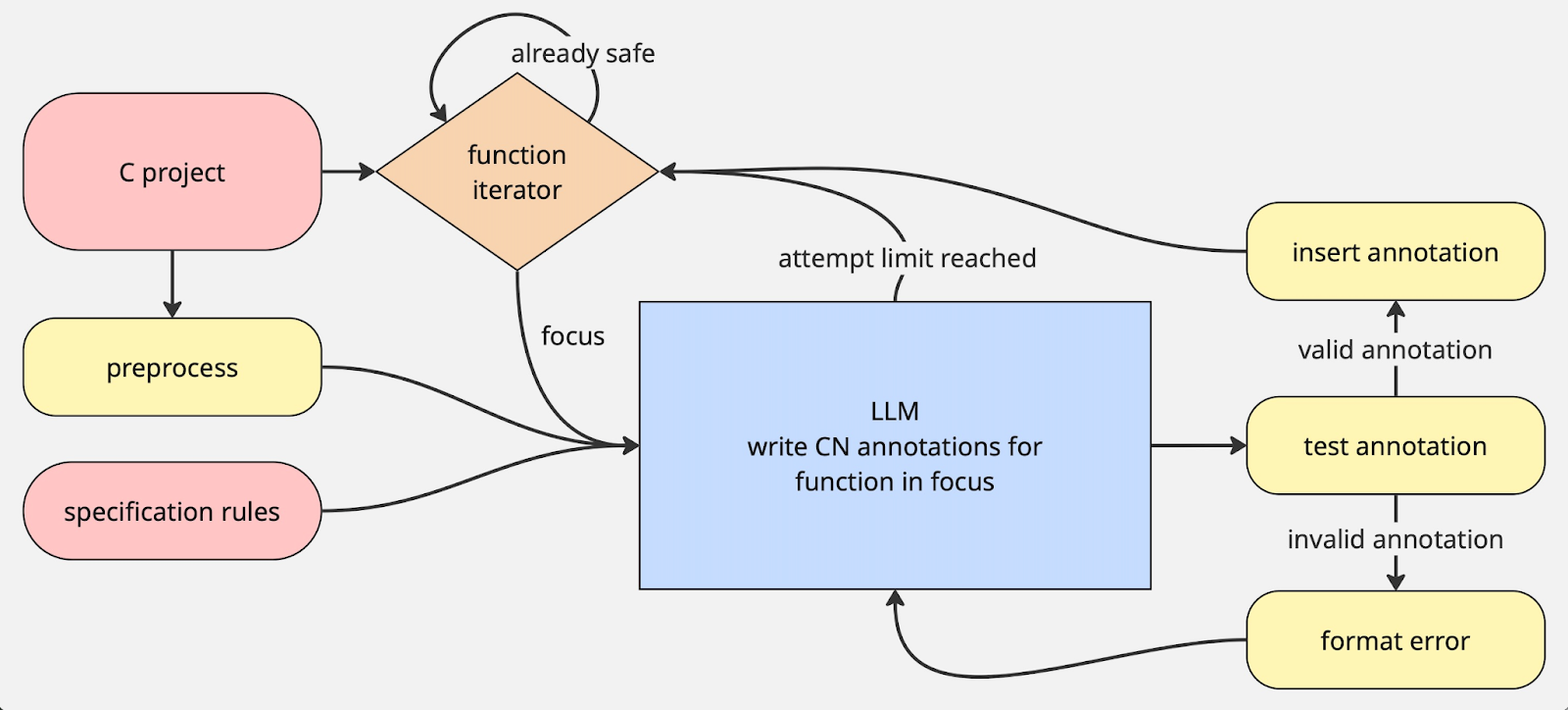
There are three potential failure states for annotation:
- There does not exist a valid CN annotation for the C function, but it is safe (some safe functions don’t have valid CN specifications, due to the complexities of C memory access);
- A valid CN annotation exists, but CNnotator cannot find it;
- The C code is inherently unsafe (usually, it contains a bug) in which case there cannot exist a valid annotation.
CNnotator tries to distinguish the last case from the first two. If it decides that a function is inherently unsafe, e.g., the function contains a use-after-free or a double-free, it inserts a comment declaring that no annotation could ensure safety. It also records its reasoning in a separate file so the user can see how to change their code to make it safe.
We tested CNnotator on a small dataset of functions scavenged from the wild or created by Claude Sonnet, o3, or myself. We found that CNnotator can handle basic memory usage patterns quite easily. For example, it knows that a function requires ownership of pointers passed in, and must return ownership of those passed out. It can annotate long and complex functions and those with loops. Beyond basic pointers, it can handle C projects utilizing arrays, global variables, and macros. CNnotator feeds the whole project to the LLM so that it can extrapolate memory interdependence properties between functions, which lets it generate more useful, context-aware specifications.

We tested CNnotator across a number of different OpenAI LLMs with varying capabilities. CNnotator successfully annotates most functions, even when using weaker models. This aligns with previous experiments at Galois that suggest LLMs effectively understand C code.
There are two main classes of LLMs: reasoning models, which are designed for tasks involving logic, and chat models, which are designed to…well…chat. OpenAI’s reasoning model o3, released April 2025, was able to synthesize annotations for 28 of the 31 annotatable functions in the test set on its first attempt, and was only unable to annotate one function within three attempts. That is, given one try it could annotate 90% of the test set, and 97% within three. The chat model GPT-4o was released in August 2024, making it the second oldest model OpenAI offers through its API. Yet, it was still able to annotate 65% of functions on its first attempt.
Clever girl…
I was quite pleased to see how well I could get CNnotator to perform: it’s a promising step forward in the larger quest to automate (or dramatically speed up) the translation of C code to safe Rust. It can synthesize annotations for multi-function, multi-file C projects with memory manipulation and various data structures. Its usage of LLMs allows it to generate holistic specifications that prepare the file for direct conversion to safe Rust, skipping the intermediate step to unsafe Rust. CNnotator was easy to develop, and is easy to use. Now, Galois is working on pushing C to safe Rust capabilities over the finish line as part of DARPA’s TRACTOR program, and I’m excited to see what happens next!

My perspectives on LLMs haven't fully shifted. LLMs are clumsy and inelegant, and they do make my formal methods brain scream. But in building CNnotator, I found that, for some projects in formal methods, LLMs are not simply one of many potential tools, but the best and perhaps the only fit for the job. CNnotator proved that to me: now I’m willing to pass my keyboard to some simians, even if I’m not going ape over it.
Honestly, I don’t even like Jurassic Park that much. I just used it because it was a good narrative tool for this blog post. I’m still not a fan of LLMs, but I’ve come around to recognising them, too, as an occasionally useful tool. We shouldn’t, and don’t, let stories like Jurassic Park steer us away from doing good work manipulating genes, like treating sickle cell anemia with CRISPR. Perhaps the same spirit of innovation for good can apply to LLMs in computer science. Because, sometimes, after stopping to think whether we scientists not only can but should try something new, we find the answer to be “yes.”

